

ALGORITHMIQUE
Les problèmes algorithmiques du traitement de l'information
Méthodes de tri
Le problème du tri consiste, étant donné une suite x = (x1, x2, ..., xn) d'éléments d'un ensemble totalement ordonné – par exemple N ou R –, à déterminer une permutation σ de 1, ..., n telle que :
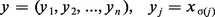
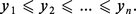
L'algorithme de tri par échanges consécutifs, TEC, est conceptuellement le plus simple. Il consiste en (n − 1) phases successives :
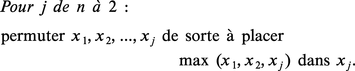
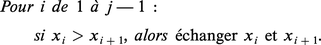

La complexité d'un algorithme de tri tel que TEC se mesure par le nombre de comparaisons effectuées et par le nombre de déplacements d'éléments de la suite (sur l'exemple, dix comparaisons et sept échanges). Dans le cas de l'algorithme TEC appliqué à une suite de longueur n, le nombre de comparaisons vaut exactement :
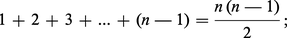
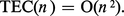
De nombreux algorithmes de tri élémentaires possèdent une complexité en O(n2). Comme dans le cas des algorithmes arithmétiques, une conception récursive conduit à une réduction importante de complexité.
L'algorithme de tri-fusion est ainsi fondé sur le principe suivant : Supposons n pair, n = 2 m ; pour trier x1, x2, ..., xn, on trie séparément x1, x2, ..., xm et xm+1, xm+2, ..., xn. Soit u = (u1, u2, ..., um) et v = (v1, v2, ..., vm) les résultats de ces deux tris. On obtient la suite y correspondant au tri de x par la fusion (ou interclassement) des suites u et v, l'algorithme de fusion étant défini récursivement par :
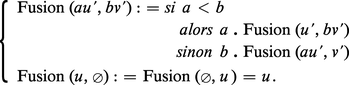
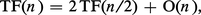
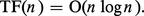
Parmi les autres méthodes de tri récursif de complexité O(n log n), la plus connue est le tri-partition, encore appelé « tri rapide » (Hoare, 1962). Le tri-partition de x = (x1, x2, ..., xn) correspond à la suite de calculs :
(a) séparer x en deux sous-ensembles x′, x″ :
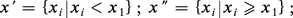
(b) trier séparément x′ et x″, avec pour résultats y′ et y″ ;
(c) retourner le résultat global y = y′ ( y″.
L'algorithme de tri-fusion est à la base des méthodes de tri externe appliquées aux fichiers sur disque. L'algorithme de tri-partition, convenablement optimisé, est le plus rapide pour les tris en mémoire centrale d'ordinateur.
Structures de données
Une autre approche du problème du tri repose sur la construction de structures de données : il s'agit de la superposition à l'ensemble des données (un simple vecteur dans le cas du tri) d'une structure plus riche permettant un accès plus rapide aux informations ainsi complétées.
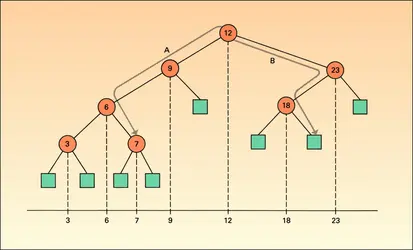
Arbre binaire
Encyclopædia Universalis France
La structure de donnée la plus importante en informatique est certainement la structure d'arbre (graphe connexe sans cycle). Étant donné une suite x = (x1, x2, ..., xn), un arbre[...]
La suite de cet article est accessible aux abonnés
- Des contenus variés, complets et fiables
- Accessible sur tous les écrans
- Pas de publicité
Déjà abonné ? Se connecter
Écrit par
- Philippe COLLARD : professeur des Universités
- Philippe FLAJOLET : ingénieur de recherche à l'Institut national de recherche en informatique et automatique (I.N.R.I.A.).
Classification
Pour citer cet article
Philippe COLLARD et Philippe FLAJOLET. ALGORITHMIQUE [en ligne]. In Encyclopædia Universalis. Disponible sur : (consulté le )
Médias
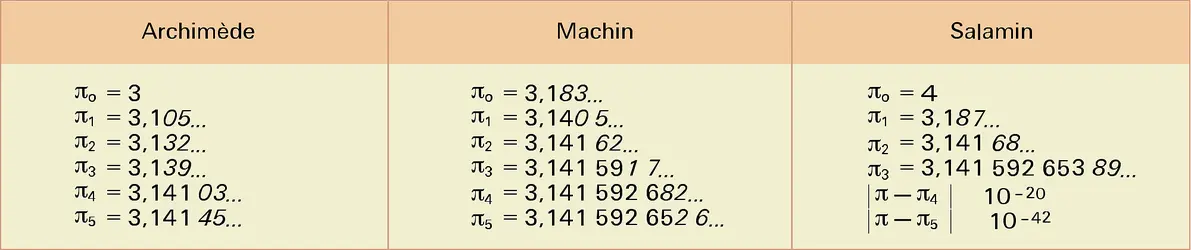
Algorithmes de calcul de p
Encyclopædia Universalis France
Arbre binaire
Encyclopædia Universalis France

Échelle de complexité
Encyclopædia Universalis France
Autres références
-
PRIX ABEL 2021
- Écrit par Bernard PIRE
- 1 014 mots
- 2 médias
Le prix Abel, qui distingue chaque année un ou plusieurs mathématiciens pour leurs contributions exceptionnelles au développement des mathématiques, a été décerné en 2021 au Hongrois László Lovász et à l’Israélien Avi Wigderson. Dix-neuf ans après la création de ce « prix Nobel des...
-
CALCUL, mathématique
- Écrit par Philippe FLAJOLET
- 1 785 mots
L'algorithmique s'attache à l'élaboration d'algorithmes efficaces pour résoudre les problèmes reconnus comme calculables. Cette discipline s'organise selon quelques grands principes généraux. Par exemple, pour traiter efficacement des problèmes de recherche d'information de forme complexe, il s'avère... -
INDE (Arts et culture) - Les mathématiques
- Écrit par Agathe KELLER
- 5 429 mots
- 3 médias
À l’indépendance, la création de centres d’excellence pour les mathématiques et une école indienne très forte, notamment en algorithmique théorique, placent définitivement l’Inde nouvellement créée sur la carte mondiale des sciences mathématiques. Si un certain nombre de mathématiciens fameux... -
ITÉRATION, mathématique
- Écrit par Jean-Paul DELAHAYE, Universalis
- 830 mots
Itérer signifie recommencer, faire à nouveau. Construire les nombres entiers peut être vu comme l'opération consistant à partir de zéro à itérer indéfiniment l'ajout d'une unité.
Plus généralement, en mathématiques, lorsqu'une fonction ou opération est disponible, il est fréquent...
- Afficher les 10 références
Voir aussi
- CODAGE
- INFORMATION, informatique et télécommunications
- NOMBRES PREMIERS
- ALGORITHMES GÉNÉTIQUES
- COLORIAGE PROBLÈME DU
- POLYGONES
- INFORMATIQUE ET MATHÉMATIQUES
- PRIMALITÉ TESTS DE
- PROGRAMMATION MATHÉMATIQUE
- FOURIER DISCRÈTE TRANSFORMATION DE (TFD)
- FERMAT PETIT THÉORÈME DE
- PI CALCUL DE
- NEWTON ALGORITHME DE
- PROGRAMMATION EN NOMBRES ENTIERS
- SALAMIN ALGORITHME DE
- TRI MÉTHODES DE, mathématiques
- ALGORITHME
- FACTORISATION
- COOLEY JAMES WILLIAM (1926-2016)
- TUCKEY JOHN WILDER (1915-2000)
- FOURIER RAPIDE TRANSFORMÉE DE ou FTP (Fast Fourier Transform)
- P PROBLÈME, théorie de la complexité
- NP PROBLÈME, théorie de la complexité
