

TRAITEMENT AUTOMATIQUE DES LANGUES
- 1. Pourquoi l’analyse de la langue par ordinateur est-elle difficile ?
- 2. Les domaines de recherche en traitement automatique des langues
- 3. L’évaluation des systèmes de traitement automatique des langues
- 4. Les grands domaines d’application du traitement automatique des langues
- 5. Conclusion
- 6. Bibliographie
Le traitement automatique des langues (TAL) est un domaine de recherche pluridisciplinaire à l’intersection de la linguistique et de l’informatique – et désormais de l’intelligence artificielle, ou plus précisément de l’apprentissage artificiel. En guise de définition liminaire, on peut dire que le TAL concerne essentiellement l’analyse des langues au moyen d’un ordinateur. Le TAL est également connu sous diverses appellations qui traduisent parfois des nuances au sein de ce vaste domaine de recherche : on parle par exemple d’« ingénierie linguistique », quand l’accent est mis sur les aspects pratiques et opérationnels, ou de « linguistique informatique », quand c’est la linguistique qui tient un rôle important dans les recherches. Cette définition peut paraître néanmoins trop restrictive dans la mesure où le TAL recouvre également la « génération de texte », c’est-à-dire la production et non plus l’analyse automatique de textes. Ce champ de recherche et d’application est populaire, à l’heure des agents conversationnels et autres « gadgets » fondés sur une interaction avec l’utilisateur – pour qu’il y ait interaction, il faut prévoir à la fois une étape d’analyse et une étape de génération.
Il faut d’emblée souligner que le TAL a connu des mutations extrêmement importantes en quelques années, et que ce qui se fait aujourd’hui sur le plan technique n’a plus grand-chose à voir avec ce qui se faisait avant les années 2000. Du point de vue du grand public, le domaine a longtemps été connu essentiellement à travers les correcteurs orthographiques et les traducteurs automatiques, qui étaient de surcroît souvent de qualité médiocre. À l’inverse, il existe désormais de plus en plus d’applications visibles, opérationnelles et relativement efficaces. Tous les problèmes ne sont pas résolus et les systèmes automatisés font toujours des erreurs, mais un certain nombre de réussites sont indéniables. La qualité des traductions, au moins entre une vingtaine de langues, est de plus en plus satisfaisante. Il est ainsi possible de converser avec un agent artificiel de manière relativement efficace (on pensera à Siri d’Apple, à OK Google ou à Alexa d’Amazon). Les moteurs de recherche sont de plus en plus précis et corrigent d’eux-mêmes certaines fautes de frappe, suggèrent des alternatives, etc.
Cette évolution s’explique par des progrès extrêmement importants, qui concernent moins la linguistique, et qui sont avant tout d’ordre technique. Deux éléments principaux expliquent pour l’essentiel les progrès obtenus à partir des années 1990, même si l’apprentissage profond (deeplearning) a accentué cette tendance : d’une part, la masse de données textuelles disponible sur Internet ; d’autre part, la puissance de calcul des machines, en constante augmentation. Le développement de ce que l’on appelle l’« intelligence artificielle » et, au sein de ce domaine, celui de l’« apprentissage artificiel » ont considérablement renouvelé le TAL : contrairement à ce que l’on pensait il y a encore quelques décennies, il est extrêmement efficace d’« apprendre » depuis les données.
Pourquoi l’analyse de la langue par ordinateur est-elle difficile ?
Le TAL est difficile parce que l’ordinateur n’a a prioriaucune connaissance de la langue. Il faut donc lui indiquer ce qu’est un mot, une phrase, etc. Jusque-là, les choses peuvent sembler relativement simples. Il faut pourtant bien voir que, dès ce niveau, la langue est complexe et ambiguë. Prenons deux exemples. L’apostrophe marque l’élision d’une lettre entre deux mots, comme dans « l’éléphant », mais ce n’est pas toujours le cas : une séquence comme « aujourd’hui » est généralement considérée comme formant un seul mot, qui possède pourtant une apostrophe, laquelle ne joue plus alors son rôle de séparateur. Le trait d’union pose[...]
- 1. Pourquoi l’analyse de la langue par ordinateur est-elle difficile ?
- 2. Les domaines de recherche en traitement automatique des langues
- 3. L’évaluation des systèmes de traitement automatique des langues
- 4. Les grands domaines d’application du traitement automatique des langues
- 5. Conclusion
- 6. Bibliographie
La suite de cet article est accessible aux abonnés
- Des contenus variés, complets et fiables
- Accessible sur tous les écrans
- Pas de publicité
Déjà abonné ? Se connecter
Écrit par
- Thierry POIBEAU : directeur de recherche au CNRS
Classification
Pour citer cet article
Thierry POIBEAU. TRAITEMENT AUTOMATIQUE DES LANGUES [en ligne]. In Encyclopædia Universalis. Disponible sur : (consulté le )
Médias

Texte analysé par un analyseur morphosyntaxique
Encyclopædia Universalis France

Analyse syntaxique d’une même phrase dans quatre langues différentes
Encyclopædia Universalis France
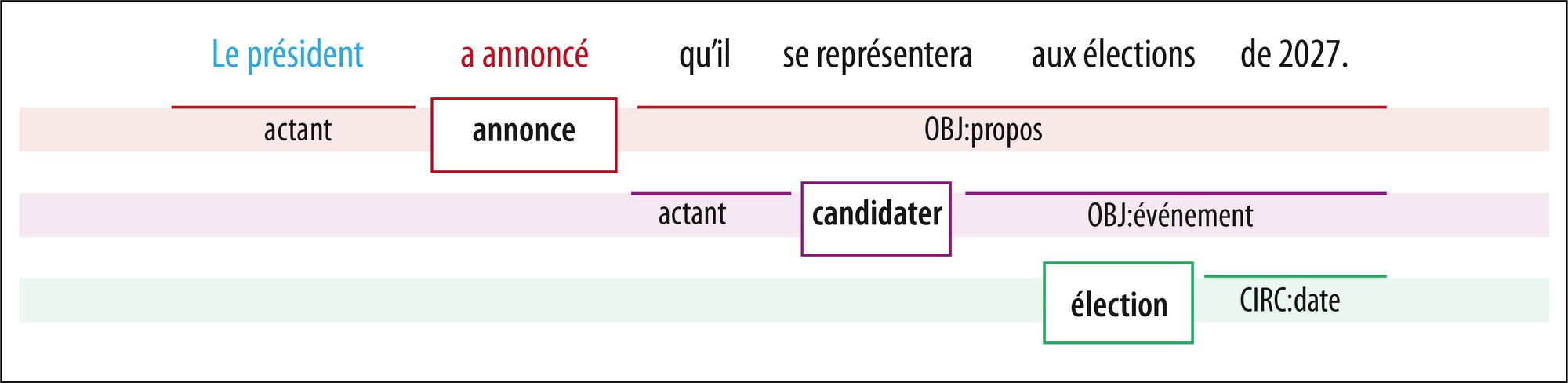
Analyse sémantique des prédicats et de leurs arguments selon la théorie Frame Semantics
Encyclopædia Universalis France
Autres références
-
LANGAGE ACQUISITION DU
- Écrit par Michèle KAIL
- 4 950 mots
- 3 médias
...s’ajoutent des indications concernant les gestes et les regards ainsi que les phénomènes d’interaction avec l’entourage. L’informatique permet le stockage, le traitement automatique et le transfert des données, entraînant un véritable changement d’échelle dans les pratiques de recherche. L’étude des productions... -
COGNITIVES SCIENCES
- Écrit par Daniel ANDLER
- 19 262 mots
- 4 médias
 ...scinder en une branche théorique proche de la logique appliquée et une branche d'ingénierie informatique, divisée à son tour en spécialités telles que le traitement automatique des langues (T.A.L.), la vision artificielle, les images de synthèse, la reconnaissance vocale, et différentes techniques de ...
...scinder en une branche théorique proche de la logique appliquée et une branche d'ingénierie informatique, divisée à son tour en spécialités telles que le traitement automatique des langues (T.A.L.), la vision artificielle, les images de synthèse, la reconnaissance vocale, et différentes techniques de ... -
DICTIONNAIRE
- Écrit par Bernard QUEMADA
- 7 965 mots
- 1 média
Les progrès de l'informatique éditoriale et destraitements automatiques de la langue et des textes ont bouleversé le travail des dictionnaristes autant que leurs produits dans les dernières années du xxe siècle. Ces transformations, plus profondes encore que celles entraînées par l'imprimerie,... -
HARRIS ZELLIG SABBETAI (1909-1992)
- Écrit par Morris SALKOFF
- 1 063 mots
La recherche de Zellig Sabbetai Harris est intimement liée aux travaux de l'école américaine d'analyse distributionnelle qui a élaboré son programme pour la linguistique dans les années 1930 et 1940, sous l'impulsion de E. Sapir et L. Bloomfield. Ce dernier avait proposé d'abstraire...
- Afficher les 12 références
Voir aussi
- CONTENU ANALYSE DE
- DOCUMENT
- MODÈLE, linguistique
- LEXICOLOGIE
- ÉVALUATION
- LEXIQUE
- CLASSIFICATION
- FRANÇAISE LANGUE
- INFORMATIQUE & SCIENCES HUMAINES
- INTERDISCIPLINAIRES ou PLURIDISCIPLINAIRES RECHERCHES
- LINGUISTIQUE APPLIQUÉE
- SYSTÈME EXPERT
- DIALOGUE HOMME-MACHINE
- INFORMATIQUE DOCUMENTAIRE
- RECONNAISSANCE AUTOMATIQUE DE LA PAROLE
- GÉNÉRATION AUTOMATIQUE DE TEXTES
- FONDS D'ARCHIVES
- AGENT CONVERSATIONNEL ou CHATBOT
