
STATISTIQUE
- Article mis en ligne le
- Modifié le
- Écrit par Georges MORLAT
Analyse des données
Mis en présence de données, le statisticien peut se voir assigner une assez grande variété d'objectifs ; la statistique lui offre les méthodes adaptées à ces objectifs. Ceux-ci peuvent être, par exemple, de présenter les observations, ou de les traiter de telle façon que soit suggérée une explication des phénomènes, ou encore de répondre à une question précise concernant une théorie scientifique (les observations sont-elles en accord avec la théorie ?) ou des aspects non directement observables de la réalité, ou enfin d'éclairer une décision particulière. Certains de ces objectifs peuvent être atteints par des méthodes de traitement des données n'impliquant apparemment aucune hypothèse sur les phénomènes étudiés : ces méthodes sont groupées sous l'expression d'analyse des données. D'autres objectifs impliquent que le statisticien introduise, sous forme d'un modèle probabiliste, les théories qu'il veut vérifier ou préciser (inférence statistique) ou les conséquences possibles du choix d'une action (décision statistique).
En analyse des données, il s'agit donc de « décrire » un ensemble de données. Dans la période classique de la statistique mathématique (première moitié du xxe siècle), on ne disposait de méthodes efficaces que pour des statistiques unidimensionnelles ou bidimensionnelles ; c'est seulement grâce aux ordinateurs que l'on peut traiter, sans trop les appauvrir, des tableaux d'observations de dimensions quelconques.
Statistique descriptive
Pour un phénomène unidimensionnel, une statistique est un ensemble de n mesures {x1, x2, ..., xn} ; on dit que c'est un n-échantillon. On peut le représenter aussi bien comme un n-uple de points de R que comme un point de Rn. Les méthodes statistiques élémentaires (statistique descriptive) s'attachent à décrire de tels objets. On définit ainsi des caractéristiques de valeur centrale : d'une part, la moyenne arithmétique :


Les choix d'une caractéristique de valeur centrale et d'une caractéristique de dispersion doivent être cohérents : ils sont liés au choix d'une distance dans Rn permettant de comparer deux échantillons. Ainsi, avec la distance euclidienne classique, si on cherche le point de coordonnées toutes égales ṯ = (t, t, ..., t), le plus proche de l'échantillon x̱ = (x1, x2, ..., xn), on trouve qu'il faut prendre t = x̄, et que la distance entre ṯ et x̱ est alors √ ns.
La représentation graphique d'un échantillon se fait à l'aide de l' histogramme, ou polygone des fréquences. On utilise aussi le diagramme des fréquences cumulées, ou fonction de répartition.
Pour le cas d'un échantillon d'un couple de deux variables, nous aurons par exemple :

Un tel échantillon peut être considéré comme un n-uple de points dans R2 ou comme un couple de points dans Rn. Les caractéristiques usuelles « au second ordre » d'un tel échantillon sont les valeurs moyennes x̄ et ȳ, les écarts types sx et sy, et le coefficient de corrélation :
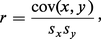
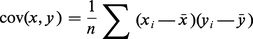
Le coefficient de corrélation n'est pas affecté par une transformation affine sur l'une ou l'autre des variables x et y. On montre sans peine qu'il est compris entre − 1 et + 1. D'un point de vue géométrique, lorsqu'on représente l'échantillon par un couple de points de Rn, le[...]
La suite de cet article est accessible aux abonnés
- Des contenus variés, complets et fiables
- Accessible sur tous les écrans
- Pas de publicité
Déjà abonné ? Se connecter
Écrit par
- Georges MORLAT : professeur à l'université de Paris-VI
Classification
Pour citer cet article
Georges MORLAT. STATISTIQUE [en ligne]. In Encyclopædia Universalis. Disponible sur : (consulté le )
Article mis en ligne le et modifié le 14/03/2009
Média

Tableau de correspondance
Encyclopædia Universalis France
Autres références
-
APPROCHES TRANSVERSALE ET LONGITUDINALE EN PSYCHOLOGIE DU DÉVELOPPEMENT
- Écrit par Henri LEHALLE
- 1 044 mots
S’informer sur le développement des enfants et des adolescents impose de pouvoir comparer leurs comportements aux différents âges. Pour cela, diverses approches méthodologiques sont possibles.
Selon une première approche « transversale », les groupes d’âge à comparer sont constitués par des...
-
ASSURANCE - Histoire et droit de l'assurance
- Écrit par Jean-Pierre AUDINOT , Encyclopædia Universalis et Jacques GARNIER
- 7 490 mots
- 1 média
 Pour que cet aléa disparaisse, il fallut attendre que la découverte du calcul des probabilités et le progrès de l'observation statistique permettent une prévision rationnelle du risque. Mais ce n'est qu'au xviie siècle que Pascal, à la demande d'un joueur de cartes passionné, le chevalier...
Pour que cet aléa disparaisse, il fallut attendre que la découverte du calcul des probabilités et le progrès de l'observation statistique permettent une prévision rationnelle du risque. Mais ce n'est qu'au xviie siècle que Pascal, à la demande d'un joueur de cartes passionné, le chevalier... -
BAYES THOMAS (1702-1761)
- Écrit par Bernard PIRE
- 311 mots
Mathématicien britannique, pionnier de la statistique. Né en 1702 à Londres, Thomas Bayes est le fils d'un des six premiers pasteurs non conformistes à être ordonnés après le refus en 1664 d'une partie de l'Église anglicane d'adhérer à l'Act of Uniformity. Après avoir reçu une solide éducation privée,...
-
BERNSTEIN FELIX (1878-1956)
- Écrit par Bernard PIRE
- 337 mots
Mathématicien allemand naturalisé américain, spécialiste de la théorie des ensembles puis des statistiques appliquées. Né le 24 février 1878 à Halle (Allemagne), Felix Bernstein est le fils d'un spécialiste de l'électrobiologie. Élève de Georg Cantor (1845-1918) à Halle, Bernstein...
- Afficher les 80 références
