
STATISTIQUE
Inférence statistique classique
Les méthodes que nous avons décrites au chapitre précédent sous le titre d'analyse des données concernent la description des tableaux d'observations statistiques et ne font intervenir aucune hypothèse sur l'origine de ces données. La statistique classique était au contraire une statistique probabiliste, fondée sur la prise en considération des lois de probabilité auxquelles obéissent les phénomènes naturels, objets d'observation. On décrira maintenant les principes et les méthodes de la statistique classique.
Théorie de l'échantillonnage
Tout, dans la statistique classique, repose sur l'étude des distributions des échantillons. Pour la statistique classique, un échantillon est défini dans le cas le plus simple comme un ensemble d'épreuves indépendantes et de même loi. Il convient d'abord d'étudier la distribution de probabilité de tels échantillons, dont on donnera quelques exemples. Soit x une variable aléatoire suivant une loi de Laplace-Gauss de moyenne m, d'écart type σ, et soit :
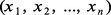
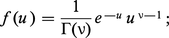
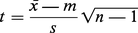
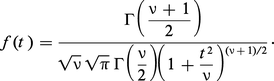
De même, étant donné un échantillon d'une loi de Laplace-Gauss à deux variables, soit :

Une autre loi de distribution d'échantillonnage couramment utilisée dans la statistique classique est celle du quotient de deux variances indépendantes (ou de deux χ2) ; elle est connue sous le nom de loi de Fisher-Snedecor. Un certain nombre d'autres lois, que suivent les grandeurs caractérisant des échantillons de variables gaussiennes, ont été étudiées et tabulées. Les premiers statisticiens, au début du siècle, utilisaient de tels résultats à l'aide d'un principe de raisonnement extrêmement simple : les grandeurs calculées à partir d'un échantillon étant choisies de façon quelque peu intuitive, on convenait que des valeurs de probabilité très petites ne devaient pas se produire, ou plus précisément qu'il était raisonnable de « faire comme si » des valeurs de probabilité très petites ne s'étaient pas produites. La statistique mathématique a donné peu à peu une forme cohérente à ce type de raisonnement. Nous donnerons comme exemples quelques-unes des théories développées à cet effet.
Théorie de l'estimation
Supposons qu'une grandeur observable x suive une loi de probabilité dépendant d'un paramètre θ et possédant une densité f(x, θ) ; on dispose d'un échantillon de valeurs données, soit x1, x2, ..., xn, et on veut se faire une idée de la valeur du paramètre inconnu θ. On peut préciser cet énoncé de plusieurs façons. La plus simple conduit à poser le problème de l'estimation ponctuelle[...]
La suite de cet article est accessible aux abonnés
- Des contenus variés, complets et fiables
- Accessible sur tous les écrans
- Pas de publicité
Déjà abonné ? Se connecter
Écrit par
- Georges MORLAT : professeur à l'université de Paris-VI
Classification
Pour citer cet article
Georges MORLAT. STATISTIQUE [en ligne]. In Encyclopædia Universalis. Disponible sur : (consulté le )
Article mis en ligne le et modifié le 14/03/2009
Média

Tableau de correspondance
Encyclopædia Universalis France
Autres références
-
APPROCHES TRANSVERSALE ET LONGITUDINALE EN PSYCHOLOGIE DU DÉVELOPPEMENT
- Écrit par Henri LEHALLE
- 1 044 mots
S’informer sur le développement des enfants et des adolescents impose de pouvoir comparer leurs comportements aux différents âges. Pour cela, diverses approches méthodologiques sont possibles.
Selon une première approche « transversale », les groupes d’âge à comparer sont constitués par des...
-
ASSURANCE - Histoire et droit de l'assurance
- Écrit par Jean-Pierre AUDINOT , Encyclopædia Universalis et Jacques GARNIER
- 7 490 mots
- 1 média
 Pour que cet aléa disparaisse, il fallut attendre que la découverte du calcul des probabilités et le progrès de l'observation statistique permettent une prévision rationnelle du risque. Mais ce n'est qu'au xviie siècle que Pascal, à la demande d'un joueur de cartes passionné, le chevalier...
Pour que cet aléa disparaisse, il fallut attendre que la découverte du calcul des probabilités et le progrès de l'observation statistique permettent une prévision rationnelle du risque. Mais ce n'est qu'au xviie siècle que Pascal, à la demande d'un joueur de cartes passionné, le chevalier... -
BAYES THOMAS (1702-1761)
- Écrit par Bernard PIRE
- 311 mots
Mathématicien britannique, pionnier de la statistique. Né en 1702 à Londres, Thomas Bayes est le fils d'un des six premiers pasteurs non conformistes à être ordonnés après le refus en 1664 d'une partie de l'Église anglicane d'adhérer à l'Act of Uniformity. Après avoir reçu une solide éducation privée,...
-
BERNSTEIN FELIX (1878-1956)
- Écrit par Bernard PIRE
- 337 mots
Mathématicien allemand naturalisé américain, spécialiste de la théorie des ensembles puis des statistiques appliquées. Né le 24 février 1878 à Halle (Allemagne), Felix Bernstein est le fils d'un spécialiste de l'électrobiologie. Élève de Georg Cantor (1845-1918) à Halle, Bernstein...
- Afficher les 80 références
