

INFORMATION GÉNÉTIQUE
Articles
-
ADN ET INFORMATION GÉNÉTIQUE
- Écrit par Nicolas CHEVASSUS-au-LOUIS
- 239 mots
Jusqu'en 1944, on ignorait quelle pouvait être la nature chimique de la molécule présente dans les chromosomes et porteuse de l'information génétique. Alors que la plupart des chercheurs pensaient qu'il s'agissait de protéines, deux publications viennent montrer, en 1944, qu'il...
-
MITOSE
- Écrit par Nina FAVARD
- 6 519 mots
- 5 médias
L'aphorisme omnis cellula e cellula (« toute cellule est issue d'une autre cellule ») a permis aux biologistes de comprendre que, au cours des générations cellulaires successives, la transmission de l'information génétique obéissait à des mécanismes d'une grande précision....
-
MÉIOSE
- Écrit par Marguerite PICARD, Denise ZICKLER
- 4 645 mots
- 7 médias
...de l' hérédité. On admettra donc simplement que tous les caractères qui définissent un individu sont déterminés par les gènes, unités d' information génétique portés par les chromosomes, et occupant sur ce dernier une place précise ou locus. Si l'information génétique d'un ... -
ADN (acide désoxyribonucléique) ou DNA (deoxyribonucleic acid)
- Écrit par Michel DUGUET, Universalis, David MONCHAUD, Michel MORANGE
- 10 074 mots
- 10 médias
Une fois connue la structure du matériel génétique, il fallait comprendre comment celui-ci pouvait contrôler la synthèse des protéines, molécules responsables des fonctions élémentaires de la cellule, et en particulier des fonctions de catalyse enzymatique. Dès 1940, les Américains George Beadle et... -
BIOCHIMIE
- Écrit par Pierre KAMOUN
- 3 880 mots
- 5 médias
...l'ensemble des réactions qui permettent l'expression et la transmission du message génétique. C'est donc la biochimie de l' ADN, qui est le vecteur de l'information génétique. L'ADN est connu depuis 1869, mais ce n'est qu'en 1944 qu'Avery, Mac Leod et Mc Carty démontrèrent que l'ADN pouvait être le vecteur... -
BIOTECHNOLOGIES
- Écrit par Pierre TAMBOURIN
- 5 368 mots
- 4 médias
La connaissance des séquences nucléotidiques de l'ADN constitue le niveau le plus fin del'information génétique. Dans les années 1990, la biologie à grande échelle naît de la nécessité d'augmenter fortement la puissance des techniques de séquençage de cette molécule géante, en particulier pour... -
CELLULE - L'organisation
- Écrit par Pierre FAVARD
- 11 028 mots
- 15 médias
...refermé sur lui-même et reployé de nombreuses fois (fig. 1b). C'est une molécule circulaire d'acide désoxyribonucléique ( ADN) qui forme le chromosome bactérien parce qu'il est porteur de l'identité de l'espèce, codée dans la structure de la molécule. Celle-ci est donc qualifiée d'informationnelle. -
CELLULE - La division
- Écrit par Marguerite PICARD
- 4 983 mots
- 3 médias
En ce qui concerne les organites cellulaires porteurs d'information génétique ( mitochondries de toutes les cellules, plastes des cellules végétales), la réplication de leur ADN n'est pas synchrone avec celle de l'ADN nucléaire. Elle peut être continue pendant tout le cycle cellulaire (c'est le cas... -
DÉCRYPTAGE DU CODE GÉNÉTIQUE
- Écrit par Nicolas CHEVASSUS-au-LOUIS
- 223 mots
- 1 média
Au début des années 1960, l'Américain Marshall W. Nirenberg découvre que l'addition d'un acide ribonucléique messager (ARNm) constitué uniquement d'uridine (U, un des quatre nucléotides) à un extrait bactérien suffit à déclencher la synthèse d'une protéine composée uniquement de phénylalanine....
-
ÉVOLUTION
- Écrit par Armand de RICQLÈS, Stéphane SCHMITT
- 15 123 mots
- 10 médias
...en cause, car tout l'édifice arborescent de la systématique est fondé sur la prémisse d'une transmission verticale (d'une génération à la suivante) de l'information génétique. Or la biologie moléculaire révèle désormais l'existence d'importants « transferts horizontaux » d'informations génétiques entre... -
GÉNÉTIQUE
- Écrit par Axel KAHN, Philippe L'HÉRITIER, Marguerite PICARD
- 25 873 mots
- 31 médias
...monomères et surtout l'ordre dans lequel ils se succèdent le long de la séquence. Parce qu'il représente un choix à l'intérieur de ce vaste ensemble, chaque type individuel de macromolécule possède, comme une phrase, une véritable signification ;il est porteur d'une certaine quantité d'information. -
GÉNIE GÉNÉTIQUE
- Écrit par Louis-Marie HOUDEBINE
- 3 338 mots
- 6 médias
Les messages qui sont contenus dans l'ADN sont directement liés à l'ordre des bases qui constituent cette molécule. Le code génétique (fig. 2) définit les messages qui déterminent la structure des protéines. D'autres informations codées sont présentes dans l'ADN. C'est le cas, notamment, pour les éléments... -
GÉNOMIQUE - Théorie et applications
- Écrit par Louis-Marie HOUDEBINE
- 4 042 mots
L'ensemble des bases de l'ADN contient la totalité des messages génétiques d'un organisme. Ces messages sont de multiples natures. Ceux qui correspondent aux régions transcrites et, par conséquent, aux protéines sont codés selon un système parfaitement connu, le code génétique... -
HÉRÉDITÉ
- Écrit par Charles BABINET, Luisa DANDOLO, Jean GAYON, Simone GILGENKRANTZ
- 11 231 mots
- 7 médias
...obtient assez aisément un début de développement de l'œuf vierge, l'embryon parthénogénétique meurt précocement et, en aucun cas, ne se développe à terme. La raison de cet échec est liée à un phénomène découvert au début des années 1980 que les auteurs anglo-saxons nomment genomic imprinting et que... -
INFORMATION THÉORIE DE L'
- Écrit par Henri ATLAN, Jean-Paul DELAHAYE, Étienne KLEIN
- 3 063 mots
...préciser la fonction biologique des molécules d'ADN. Elles ont en effet un rôle fondamental dans la transmission des caractéristiques d'un être vivant. Elles garantissent la pérennité d'une espèce, car elles constituent le génome qui la caractérise. Elles portent, en outre, la marque de l'individu : comme... -
INFORMATIQUE - Ordres de grandeur
- Écrit par Jean-Paul DELAHAYE
- 2 645 mots
- 2 médias
...cerveaux humains, sont faibles comparées à celles que l'on rencontre dans le monde de la vie sur Terre. Si, chez des animaux évolués, le cerveau stocke de l'information, en revanche, c'est chez tous les êtres vivants qu'uneinformation, dite génétique, est manipulée et conservée dans chaque cellule. -
MACROMOLÉCULES
- Écrit par Michel FONTANILLE, Yves GNANOU, Marc LENG
- 13 744 mots
- 5 médias
En fonction de la séquence des chaînons nucléotidiques dont il est constitué l'ADN est le support de l'information génétique. '''''''''' L'information génétique est conservée intégralement au cours de la division de la cellule mère en deux cellules filles. La cellule est capable de synthétiser... -
NUCLÉIQUES ACIDES
- Écrit par Jacques KRUH, Ethel MOUSTACCHI, Michel PRIVAT DE GARILHE, Alain SARASIN
- 13 468 mots
- 17 médias
Le fait fondamental a été établi dès 1944 par Oswald Avery. Celui-ci a préparé de l'ADN à partir d'une souche sauvage de pneumocoques pourvus de capsule S et a ajouté cet ADN à une souche de pneumocoques R, dépourvus de capsule. Cette addition provoque la transformation de cellule... -
ONCOGENÈSE ou CANCÉROGENÈSE ou CARCINOGENÈSE
- Écrit par Roger MONIER
- 7 292 mots
- 5 médias
Les informations génétiques qui donnent au virus du sarcome de Rous ses propriétés biologiques sont inscrites dans la séquence d'une longue molécule d'acide ribonucléique (ARN). Grâce à une étude génétique du virus, associée à une étude biochimique de la molécule d'ARN... -
PARASEXUALITÉ
- Écrit par Patrice COURVALIN, Jacques THÈZE, Patrick TRIEU-CUOT, Philippe VIGIER
- 5 363 mots
- 5 médias
...matériel génétique exogène qui peut généralement être retransmis à d'autres bactéries en dehors de la progénie. Cette transmission exogène d' information génétique est consécutive aux événements de transformation, de conjugaison ou de transduction qui conduisent donc à une véritable ... -
PHYLOGÉNOMIQUE
- Écrit par Gabriel GACHELIN
- 3 017 mots
- 1
- 2
Médias

Cellule : modifications de l'information
Encyclopædia Universalis France

Chromosome humain numéro 1
Encyclopædia Universalis France
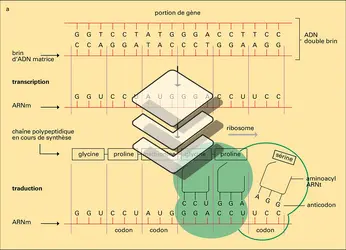
Information cellulaire
Encyclopædia Universalis France
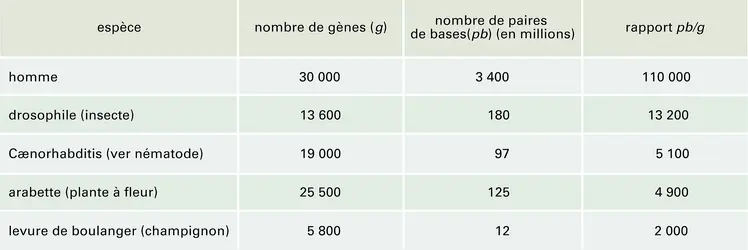
Patrimoine génétique
Encyclopædia Universalis France
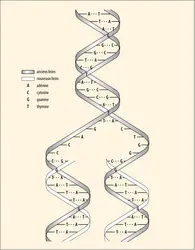
Réplication de l'ADN
Encyclopædia Universalis France
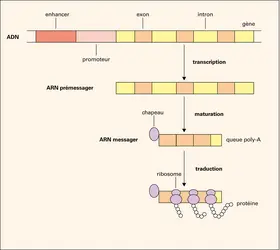
Transfert de l'information génétique
Encyclopædia Universalis France
